佛學辭彙研究應用程式界面 / Buddhist Search & Research Web API
[ 首頁 / HomePage ]
 新手上路 / Quick Start
新手上路 / Quick Start本頁以 Python 2.6 程式語言為範例,介紹 CBETA Web API 透過 XML-RPC Client 的使用方式。
* 本網頁需要使用者有最基本的 Python 程式語言概念。
* 除了 Python 外,其他程式語言同樣可透過 XML-RPC Client 進行操作。
* 詳細的功能列表及文件請參考 Function List & the Document.
1. 進入任一個 Python UI 界面(這裡以終端機模式為範例)

2. 匯入(import)XML-RPC Library('xmlrpclib' 是 Python 的 XML-RPC Library)
3. 指定 CBETA Web API 位置。(CBETA Web API 位置為 'http://140.112.26.229:51113')
* 須確定已連上網際網路,並且防火牆不會擋住 IP=140.112.26.229; post=51113 的服務。
4. 建立 CBETA Web API 的物件

5. 開始使用 CBETA Web API
5.1 取得某字串在 CBETA 中的次數。【function: getTotalNo('字串')】
* 用步驟 4 建立的物件來呼叫 getTotalNo() 並給定欲查詢的字串。
* 給定的查詢字串須是 unicode 字串或 utf8 編碼字串兩種,建議統一使用 unicode 字串。
* 回傳的結果是一個陣列,陣列的第一個元素便是給定的字串在 CBETA 中的頻率。

5.1.1 取得某字串在指定的經文範圍內的次數。
...
5.2 取得某部經文的純文字全文。【function: getSutraTexts('經號')】
* 用同樣的方式呼叫 getSutraTexts() 這個功能,這次要先準備的是經號。
* 經號使用 CBETA 完整的八位字元描述,例:T01n0001。
* 取得去掉 XML 標記及中文句逗後的完整經文,但保留段落及其他語言符號。

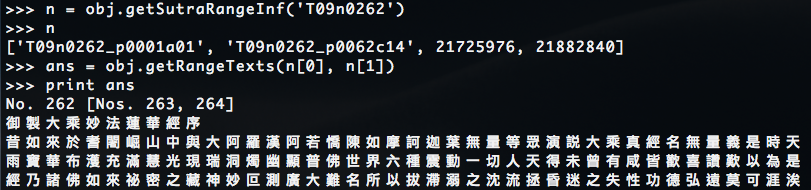
5.2.1 在某一經內取得較小範圍的全文。【function: getRangeTexts('起始行號', '結束行號')】
* 由於步驟 5.2 的功能是以經號為單位,因此大部頭經文可能需要長時間或因網路頻寬無法傳達。
* 這裡提供同一經小範圍文字的選取工具,需準備段落範圍起始及結束的行號。
* 行號使用 CBETA 完整的十七位字元描述,例:T01n0001_p0001a01。
* 以 T09n0262(妙法蓮華經)為例:
CBETA 十七位行號是從:T09n0262_p0001a01 ~ T09n0262_p0062c14
因此用 getRangeTexts('T09n0262_p0001a01', 'T09n0262_p0062c14') 將取得整個 T0262 的經文。
但如果我們改變(縮小)行號資訊則可以取得小範圍的全文資料。

* getRangeTexts() 所需的行號資訊,必須在相同一經號下才會被接受。
* 現在我們可以試試看另一個很相似的工具:getRangestxeT()
* 同樣以 T0262 第一頁上欄 1~5 行為例:

* 問題是誰知道 T0262 的開始結束行號是多少?
* 除了我們得自己想辦法取得外,這裡也另外提供一個小工具:getSutraRangeInf()
* 只要輸入八位字元的 CBETA 經號,則可以得到該經號的起始與結束行號資訊。
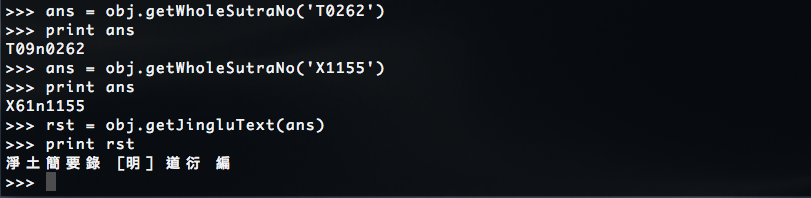
5.3 用經號取得經錄文字資料。【function: getJingluText('經號')】
* 直接看範例吧:

* 但上述幾個工具都需要提供完整八位字元的經號,我們卻常直接使用 T0262 這樣的經號,怎麼辦?
* 呼叫 getWholeSutraNo('短經號') 可以取得完整的八位字元經號資訊。
* 這裡所謂的 '短經號' 也有一定的規格:
一共五位字元,開頭為 'T' 或 'X' 後接四位數字。例:T0262, X1155 等。
* 以下提供一個小小的「連續組合技」範例:
5.4 取得 Concordance 全文檢索結果。
...
5.5 查詢某字串的前後共有哪些字元。
...
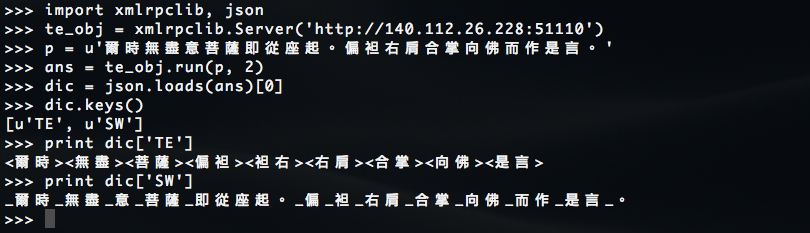
5.6 分詞及抽詞的 Web API。【function: run(u'150字以內的連續字串', 幾字詞)】
* 佛經分(抽)詞系統的 Web API 位置為: http://140.112.26.228:51110
* 分(抽)詞工具為 run(string, [2,3,4]), 須給兩個參數:
1. 欲進行分詞的 unicode string, 每次以 150 字為限。
2. 進行幾字詞的抽取及分斷(系統提供 2, 3, 4 字詞三種選向)。
* 回傳的結果是 JSON 格式的字串,可透過 json.loads()[0] 得到 Dictionary 的結果。
1. Dic['TE'] 為抽詞結果
2. Dic['SW'] 為分詞結果